- Dựa trên chính sách (Policy-Based): như REINFORCE
- Dựa trên giá trị (Value-Based): như Q-learning, Deep Q-learning
Value-based có vài vấn đề, Policy-based giải quyết được vấn đề đó, nhưng lại gặp vấn đề khác về phương sai, vậy ta giải quyết như thế nào? Kết hợp chúng lại!
Hàm cơ sở - Baseline function
Trước hết, ta tìm hiểu một cách cơ bản để giảm phương sai: chèn một hàm cơ sở \(b\) vào trong kỳ vọng
\[\nabla_\theta J(\theta) = \nabla_\theta \mathbb{E}_{\tau \sim \pi_\theta}[R(\tau)] = \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) R(\tau) \right]\]Với \(R(\tau) = \sum_{t=0}^{T} \gamma^t r_t \) và chèn hàm cơ sở \(b\) vào, ta thu được
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) \left( R(\tau) - b\right) \right]\] \[= \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) \left( \sum_{t'=0}^{T} \gamma^{t'} r_{t'} - b\right) \right]\]Hàm cơ sở không gây sai lệch (unbiased)
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) \sum_{t'=0}^{T} \gamma^{t'} r_{t'} - \textcolor{blue}{\mathbb{E}_{\tau \sim \pi_\theta} \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) b}\]Ta có
\[\textcolor{blue}{\mathbb{E}_{\tau \sim \pi_\theta} \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) b} = \sum_{a_t}^{} \pi_\theta(a_t \mid s_t) \sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) b\] \[= \sum_{a_t}^{} \sum_{t=0}^{T} \textcolor{purple}{\pi_\theta(a_t \mid s_t) \nabla_\theta \log \pi_\theta(a_t \mid s_t)} b = \sum_{a_t}^{} \sum_{t=0}^{T} \textcolor{purple}{\nabla_\theta \pi_\theta(a_t \mid s_t)} b\] \[= b \nabla_\theta \sum_{t=0}^{T} \sum_{a_t}^{} \pi_\theta(a_t \mid s_t) = b \nabla_\theta \sum_{t=0}^{T} 1 = 0\]Biểu thức này chứng minh rằng việc thêm một hàm cơ sở không gây sai lệch cho ước lượng đạo hàm, tức là không thay đổi giá trị kỳ vọng của biểu thức.
Hàm cơ sở làm giảm phương sai
Nhắc lại
\[\text{Var} \left[ X \right] = \mathbb{E} \left[ X^2 \right] - \left( \mathbb{E} \left[ X \right]\right)^2\] \[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[\underbrace{\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t)}_{\textcolor{red}{p(\tau)}} \left( R(\tau) - b\right) \right]\]Ta suy ra
\[\text{Var} \left[ \nabla_\theta J(\theta) \right] = \mathbb{E}_{\tau} \left[\left(\textcolor{red}{p(\tau)} \left( R(\tau) - b\right)\right)^2 \right] - \left( \mathbb{E}_{\tau} \left[ \textcolor{red}{p(\tau)} \left( R(\tau) - b\right) \right]\right)^2\] \[= \mathbb{E}_{\tau} \left[\left(\textcolor{red}{p(\tau)} \left( R(\tau) - b\right)\right)^2 \right] - \left( \mathbb{E}_{\tau} \left[ \textcolor{red}{p(\tau)} R(\tau) \right]\right)^2 \quad \text{(} b \text{ không gây sai lệch)}\]Ta muốn tìm giá trị nhỏ nhất của phương sai này, nên ta tính
\[\dfrac{d}{db} \text{Var} \left[ \nabla_\theta J(\theta) \right] = \dfrac{d}{db} \mathbb{E}_{\tau} \left[\left(\textcolor{red}{p(\tau)} \left( R(\tau) - b\right)\right)^2 \right]\] \[= \dfrac{d}{db} \left[ \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 R(\tau)^2 \right] -2 \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 R(\tau) b\right] + \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 b^2 \right] \right]\] \[= -2 \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 R(\tau) \right] + 2 b \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 \right]\]Giải phương trình
\[\dfrac{d}{db} \text{Var} \left[ \nabla_\theta J(\theta) \right] = 0 \Leftrightarrow \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 R(\tau) \right] = b \mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 \right]\] \[\Leftrightarrow b = \dfrac{\mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 R(\tau) \right]}{\mathbb{E}_{\tau} \left[\textcolor{red}{p(\tau)}^2 \right]}\]Vậy hàm cơ sở làm tối thiểu hóa phương sai chính là kỳ vọng của lợi nhuận trên các quỹ đạo được trọng số bởi độ lớn gradient. Tuy nhiên, chi phí tính toán độ lớn gradient lớn nên việc giảm phương sai không hiệu quả.
Do đó, người ta thường dùng một hàm cơ sở khác, là giá trị trạng thái.
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \pi_\theta(a_t \mid s_t) \left( R(\tau) - b(s_t)\right) \right]\]Actor-Critic
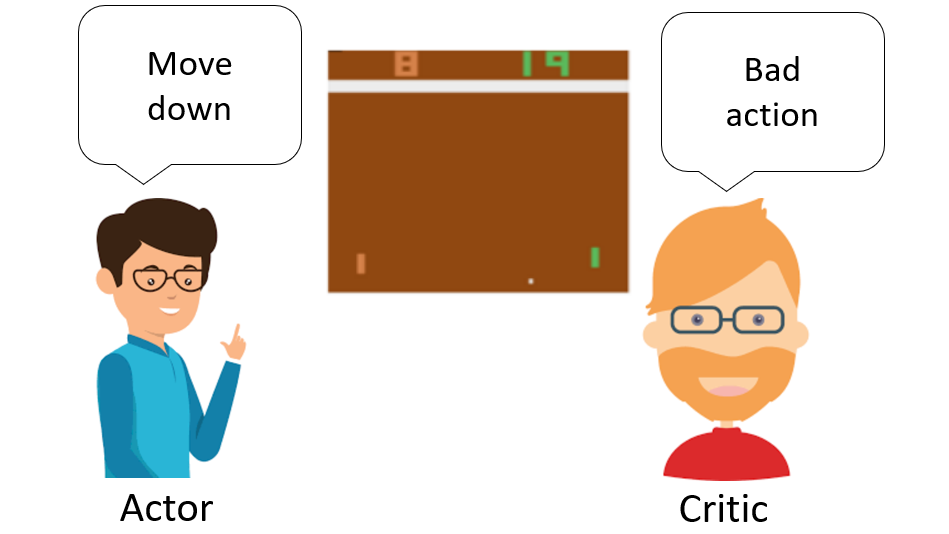
Một cách khác để giảm phương sai là dùng Actor-Critic.
Ý tưởng chính là kết hợp hai mạng: Actor - học chính sách trực tiếp để quyết định hành động và Critic - đánh giá chất lượng hành động của Actor. Qua phản hồi từ Critic, Actor cải thiện chính sách. Cả hai mạng đều học song song, cải thiện lẫn nhau qua thời gian.
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \underbrace{\pi_\theta(a_t \mid s_t)}_{\text{Actor}} \cdot \underbrace{\hat{q}_{\omega} (s_t, a_t)}_{\text{Critic}} \right]\]Rất giống với Generative Adversarial Network (GAN): Generator ra tạo ra các hình ảnh giả, còn discriminator đánh giá mức độ tốt của hình ảnh giả so với hình ảnh thực. Theo thời gian, generator có thể tạo ra những hình ảnh giả mà discriminator không thể phân biệt được.
Điều này giúp giảm phương sai và đồng thời tạo ra một chút độ lệch trong ước tính đạo hàm.
Các bước thực hiện của Actor-Critic là
-
Tại mỗi \(t\), đưa trạng thái hiện tại \(s_t\) làm đầu vào cho cả Actor và Critic.
-
Actor nhận trạng thái \(s_t\) và xuất ra một hành động \(a_t\)
-
Critic lấy trạng thái \(s_t\) và hành động \(a_t\) đấy làm đầu vào, tính giá trị của việc thực hiện hành động đó tại trạng thái đó \(\hat{q}_{\omega} (s_t, a_t)\).
\(\Rightarrow\) Trạng thái mới \(s_{t+1}\) và một phần thưởng \(r_{t+1}\)
-
Cập nhật Actor theo công thức
\[\theta \leftarrow \theta + \alpha \cdot \nabla_\theta \log \pi_\theta (a_t \mid s_t) \cdot \hat{q}_{\omega} (s_t, a_t)\] -
Dựa trên tham số đã được cập nhật, Actor tạo ra hành động tiếp theo cần thực hiện \(a_{t+1}\) dựa trên trạng thái mới \(s_{t+1}\).
-
Cập nhật Critic dựa trên MSE và semi-gradient
\[\omega \leftarrow \textcolor{lightgray}{\omega - \dfrac{\beta}{2} \cdot \nabla_\omega \left(r_{t+1} + \gamma \hat{q}_{\omega} (s_{t+1}, a_{t+1}) - \hat{q}_{\omega} (s_t, a_t) \right)^2}\] \[= \omega + \beta \cdot \left(r_{t+1} + \gamma \hat{q}_{\omega} (s_{t+1}, a_{t+1}) - \hat{q}_{\omega} (s_t, a_t) \right) \cdot \nabla_\omega \hat{q}_{\omega} (s_t, a_t)\]
Advantage Actor-Critic (A2C)
Ta có thể “nâng cấp” Actor-Critic để làm ổn định quá trình học, bằng cách dùng hàm lợi thế (Advantage function) làm Critic thay vì hàm giá trị hành động đơn giản. Hàm lợi thế này sẽ có dạng như baseline \(A(s_t,a_t) = R(\tau) - b(s_t)\)
\[\nabla_\theta J(\theta) = \mathbb{E}_{\tau \sim \pi_\theta} \left[\sum_{t=0}^{T} \nabla_\theta \log \underbrace{\pi_\theta(a_t \mid s_t)}_{\text{Actor}} \underbrace{A(s_t, a_t)}_{\text{Critic - Advantage}} \right]\]Câu hỏi tiếp theo là, làm thế nào để ước tính lợi thế khi thực hiện một hành động cụ thể trong một trạng thái cụ thể.
-
\(A(s_t,a_t) = Q(s_t,a_t) - V(s_t)\): Hàm lợi thế sẽ tính toán lợi thế tương đối của một hành động so với các hành động khác có thể thực hiện tại một trạng thái
-
Tuy nhiên, cách trên yêu cầu tính hai hàm giá trị \(Q(s_t, a_t)\) và \(V(s_t)\). Do đó, ta dùng một cách khác, chỉ dùng một mạng \(\hat{V}_{\omega}(s_t)\) là \(A(s_t, a_t) = r_{t+1} + \gamma \hat{V}_{\omega}(s_{t+1}) - \hat{V}_{\omega}(s_t)\)
Các bước thực hiện cũng tương tự như Actor-Critic, chỉ có sự khác biệt về cách cập nhật tham số
\[\theta \leftarrow \theta + \alpha \cdot \nabla_\theta \log \pi_\theta (a_t \mid s_t) \cdot A(s_t, a_t)\]và
\[\omega \leftarrow \textcolor{lightgray}{\omega - \dfrac{\beta}{2} \cdot \nabla_\omega \left(r_{t+1} + \gamma \hat{V}_{\omega} (s_{t+1}) - \hat{V}_{\omega} (s_t) \right)^2}\] \[= \omega + \beta \cdot \left(r_{t+1} + \gamma \hat{V}_{\omega} (s_{t+1}) - \hat{V}_{\omega} (s_t) \right) \cdot \nabla_\omega \hat{V}_{\omega} (s_t)\]Nhận xét
-
Actor-Critic kết hợp policy-based và value-based để giải quyết các vấn đề của riêng chúng. Điều này cũng có nghĩa là nó cải thiện được hiệu quả mẫu (sample efficiency).
-
Advantage Actor-Critic (A2C) là bản nâng cấp của Actor-Critic, giúp nó ổn định hơn. Do giảm phương sai và hiệu quả mẫu tốt hơn, A2C thường hội tụ đến chính sách tối ưu nhanh hơn REINFORCE.
-
Hiển nhiên, Actor-Critic và A2C có độ phức tạp cao hơn so với các thuật toán đơn giản như REINFORCE.