Reinforcement learning 2 - Deep Q-Learning
Published:
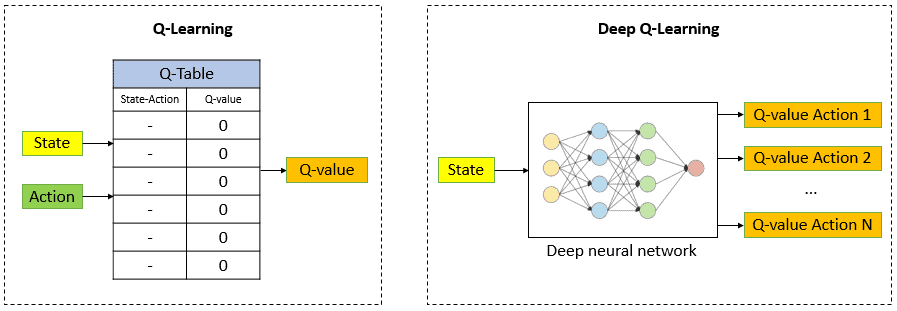
Trong Q-Learning, bảng Q phải được lưu trữ và cập nhật cho mọi trạng thái và hành động, điều này trở nên rất khó khăn khi không gian trạng thái rất lớn.
Các giá trị trạng thái trong trò chơi CartPoleBalance là liên tục, thực ra là không phù hợp với Q-learning.
Deep Learning + Q-learning = Deep Q-learning ra đời để giải quyết vấn đề này!
Deep Q-learning
Deep Q-Learning sử dụng một mạng nơ-ron (Neural network) để ước tính các giá trị Q, giúp mô hình có thể xử lý được các không gian trạng thái phức tạp và liên tục mà không cần phải lưu trữ tất cả các giá trị Q. Những gì cần làm chỉ là bỏ đi bảng Q(s,a) và thay thế bằng một mạng thần kinh đơn giản.
Trong mạng nơ-ron thì hàm mất mát là vô cùng quan trọng! Tất nhiên, hàm mất mát phải tính được sai số giữa giá trị Q dự đoán và giá trị Q mục tiêu (Q-target). Vậy thì đơn giản thôi, kết hợp TD và MSE lại. Với \(Q(s,a;\theta)\) là mạng cần học, hàm mất mát chính là
\[L(\theta) = \left( r + \gamma \cdot \max_{a'} Q(s', a'; \theta) - Q(s,a;\theta) \right)^2\]Trong đó, \(\max_{a’} Q(s’, a’; \theta)\) là dự đoán về giá trị tối ưu cho hành động tiếp theo sau khi chuyển sang trạng thái mới (chính là Q-target).
Mặc dù \(Q(s’, a’; \theta)\) phụ thuộc vào \(\theta\), người ta coi đây là một giá trị hằng số khi tính hàm mất mát, tức là không có đạo hàm ở đại lượng này.
Đây gọi là semi-gradient. Có thể hiểu rằng, tính luôn đạo hàm cho \(Q(s’, a’; \theta)\) sẽ làm thay đổi chính mục tiêu mà ta đang cố gắng học theo. Điều này dẫn đến học không ổn định, vì mục tiêu luôn “di chuyển”.
Khi đó,
\[\nabla_\theta L(\theta) = -2 \left( r + \gamma \cdot \max_{a'} Q(s', a'; \theta) - Q(s,a;\theta) \right) \nabla_\theta Q(s,a;\theta)\]Experience Replay
Trong Deep Q-Learning, Experience Replay là một kỹ thuật thường được dùng giúp cải thiện sự ổn định của quá trình huấn luyện.
Tác dụng
Tránh quên đi những trải nghiệm trước đây (hiện tượng catastrophic forgetting).
Catastrophic forgetting: Vấn đề gặp phải nếu ta cung cấp các mẫu trải nghiệm tuần tự cho mạng nơ-ron thì mạng có xu hướng quên các kinh nghiệm trước đó khi có được các kinh nghiệm mới.
Giảm mối tương quan giữa các trải nghiệm
Cách hiện thực
Ta dùng một bộ đệm (replay buffer) chứa các tuple (trạng thái, hành động, phần thưởng, trạng thái tiếp theo) để lưu các mẫu trải nghiệm mà ta có thể sử dụng lại trong quá trình huấn luyện. Bộ đệm này có giới hạn về kích thước. Khi bộ nhớ đầy, các trải nghiệm cũ nhất sẽ bị loại bỏ.
Trong mỗi bước huấn luyện, một nhóm trải nghiệm ngẫu nhiên (mini-batch) sẽ được lấy từ bộ nhớ để huấn luyện mô hình. Điều này giúp mô hình không học theo thứ tự các trải nghiệm, mà là từ một tập hợp các trải nghiệm đa dạng và không có sự phụ thuộc thời gian. Nếu tác nhân chỉ học từ các trải nghiệm liên tiếp, chúng có thể rất giống nhau và không cung cấp thông tin phong phú. Điều này cũng cho phép tác nhân học hỏi từ cùng một trải nghiệm nhiều lần.
Trong Q-learning, quá trình huấn luyện diễn ra theo các bước liên tiếp, nghĩa là mô hình học từ các trạng thái liên tiếp mà không có cơ chế lưu trữ hoặc trộn lẫn các trải nghiệm như Deep Q-learning.
Code
Code để dễ hình dung nhé!
Môi trường, Tác nhân, Mạng nơ-ron
class CartPoleEnv:
def __init__(self):
# Trạng thái: [x, x_velocity, theta, theta_velocity]
# Hành động: 0 di chuyển sang trái, 1 di chuyển sang phải
self.state = np.random.uniform(low=-0.05, high=0.05, size=(4,))
self.g = 9.8
self.m = 0.1
self.M = 1.0
self.L = 0.5
self.dt = 0.02
def step(self, action):
# Hàm dùng để mô phỏng
x, x_velocity, theta, theta_velocity = self.state
force = 20.0 if action == 1 else -20.0
cos_theta = np.cos(theta)
sin_theta = np.sin(theta)
total_mass = self.M + self.m
pole_mass_length = self.m * self.L
temp = (force + pole_mass_length * theta_velocity ** 2 * sin_theta) / total_mass
theta_acc = (self.g * sin_theta - cos_theta * temp) / (self.L * (4 / 3 - self.m * cos_theta ** 2 / total_mass))
x_acc = temp - pole_mass_length * theta_acc * cos_theta / total_mass
x += x_velocity * self.dt
x_velocity += x_acc * self.dt
theta += theta_velocity * self.dt
theta_velocity += theta_acc * self.dt
lose = x < -2.4 or x > 2.4 or theta < -np.pi / 15 or theta > np.pi / 15
reward = 1.0 if not lose else 0.0
self.state = np.array([x, x_velocity, theta, theta_velocity])
return self.state, reward, lose
def reset(self):
self.state = np.random.uniform(low=-0.05, high=0.05, size=(4,))
return self.state
class DQN(nn.Module):
def __init__(self, state_dim, action_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(state_dim, 24)
self.fc2 = nn.Linear(24, 24)
self.fc3 = nn.Linear(24, action_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
class DQNAgent:
def __init__(self, state_dim, action_dim):
self.state_dim = state_dim
self.action_dim = action_dim
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.batch_size = 32
self.model = DQN(state_dim, action_dim)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.criterion = nn.MSELoss()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_dim)
state = torch.FloatTensor(state).unsqueeze(0)
with torch.no_grad():
q_values = self.model(state)
return torch.argmax(q_values).item()
def replay(self):
if len(self.memory) < self.batch_size:
return
minibatch = random.sample(self.memory, self.batch_size)
for state, action, reward, next_state, done in minibatch:
target = reward
if not done:
next_state = torch.FloatTensor(next_state).unsqueeze(0)
target += self.gamma * torch.max(self.model(next_state)).item()
state = torch.FloatTensor(state).unsqueeze(0)
target_f = self.model(state).clone().detach()
target_f[0][action] = target
self.optimizer.zero_grad()
output = self.model(state)
loss = self.criterion(output, target_f)
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
Huấn luyện
for e in range(episodes):
state = env.reset()
total_reward = 0
for time in range(200):
action = agent.act(state)
next_state, reward, done = env.step(action)
agent.remember(state, action, reward, next_state, done)
state = next_state
total_reward += reward
if done: break
agent.replay()
if (e+1)%50 == 0: print(f"Episode {e+1}/{episodes}, Reward: {total_reward}, Epsilon: {agent.epsilon:.4f}")
Kiểm thử
def evaluate(agent, env, episodes=10):
total_rewards = []
for i in range(episodes):
state = env.reset()
total_reward = 0
lose = False
while not lose:
action = agent.act(state)
state, reward, lose = env.step(action)
total_reward += reward
print(f'Episode {i}: {total_reward}')
Fixed Q-Target
Trong hàm mất mát, mặc dù đã dùng semi-gradient, ta vẫn đang sử dụng cùng một tập tham số để ước lượng cả giá trị Q-Target lẫn giá trị Q. Do đó, tồn tại một mối tương quan nào đó giữa Q-Target và các tham số mà chúng ta đang thay đổi. Cho nên, ở mỗi bước huấn luyện, cả giá trị Q và Q-Target đều thay đổi.
Vì vậy, người ta thường
- Sử dụng một mạng riêng biệt với các tham số cố định để ước lượng giá trị Q-target. Khi đó hàm mất mát thường được viết lại là \(L(\theta) = \left( r + \gamma \cdot \max_{a'} \hat{Q}(s', a'; \theta^{-}) - Q(s,a;\theta) \right)^2\)
- Sao chép các tham số từ mạng Deep Q-Network sau mỗi \(C\) bước để cập nhật mạng này.
Nhận xét
- Với mạng nơ-ron, ta có thể xử lý đầu vào phức tạp hơn.
Với hình ảnh, ta có thể áp dụng CNN
- Deep Q-Learning đã giải quyết phần nào được vấn đề của Q-learning là xử lý được trạng thái liên tục hoặc lượng trạng thái lớn. Tuy nhiên, hành động vẫn đang là rời rạc (như di chuyển trái phải), còn liên tục (như di chuyển sang trái bao nhiêu đơn vị) thì sao?